
Photos from historic Ladino newspapers grouped together by visual similarity by the Newspaper Navigator tool
By Ben Lee
From news articles to TV shows, talk of machine learning and artificial intelligence (AI) seems to be everywhere. Indeed, these computer science algorithms show great promise for healthcare, language translation, music recommendation, and more. But how can machine learning help us to study our collective cultural heritage, in particular, the wonderfully rich Ladino-language newspapers within the University of Washington’s Sephardic Studies Digital Library?
My research in the Ph.D. program in the University of Washington’s Paul G. Allen School for Computer Science and Engineering concerns precisely this question. I am interested in using machine learning to help researchers navigate large digitized collections of materials preserved by libraries, archives, and museums. In particular, since the fall of 2019, I have been developing Newspaper Navigator, a project that seeks to shed light on the visual content preserved in the pages of historic newspaper pages, including photographs, illustrations, and advertisements.
By applying Newspaper Navigator to Ladino-language newspapers, this often-overlooked visual content reveals the richness of Sephardic communities in novel ways, from people to local events to businesses. This provides a bountiful new resource for scholarship, education, and genealogy.
Creating the Newspaper Navigator tool
Created in collaboration with LC Labs, the National Digital Newspaper Program, and IT Design & Development at the Library of Congress, as well as my advisor, Professor Daniel Weld, at the University of Washington, Newspaper Navigator originally consisted of two phases:
- Using machine learning to extract visual content from 16+ million pages in the Chronicling America archive of newspapers from 1777-1963 (resulting in the Newspaper Navigator dataset)
- Re-imagining how we search over the extracted visual content using the Newspaper Navigator search application, which allows users to search by location, keyword, and time period.
So far, the project has seen engagement from historians, educators, students, journalists, and curious members of the public.
This academic year, I am honored to be the Richard and Ina Willner Memorial Fellow at the Stroum Center, where my research focuses on applying Newspaper Navigator to Ladino-language newspapers from 1890 to 1940, published in places as far-ranging as New York and Constantinople. I am fortunate to be collaborating with Professor Devin Naar in order to study this visual content, as a lens into Ladino-language newspapers at a scale previously not possible.
Extracting visual content from 15,820 Ladino newspaper pages
How does Newspaper Navigator work? The project is built on a machine learning method known as object detection, which refers to the task of identifying and drawing bounding boxes around objects (such as cats or bicycles) present in images.
Newspaper Navigator uses bounding box annotations labeling photographs, illustrations, maps, comics and editorial cartoons — obtained as part of the Library of Congress’s Beyond Words crowdsourcing initiative, which asked volunteers to identify visual content in the Chronicling America newspaper collection — to train an object detection model to identify these classes of visual content within historic newspaper pages. This trained model can then be fed newspaper pages to be processed.
Below, I show a simulated example of what this trained machine learning model might output when given a page from the 20th-century Ladino newspaper La Vara.
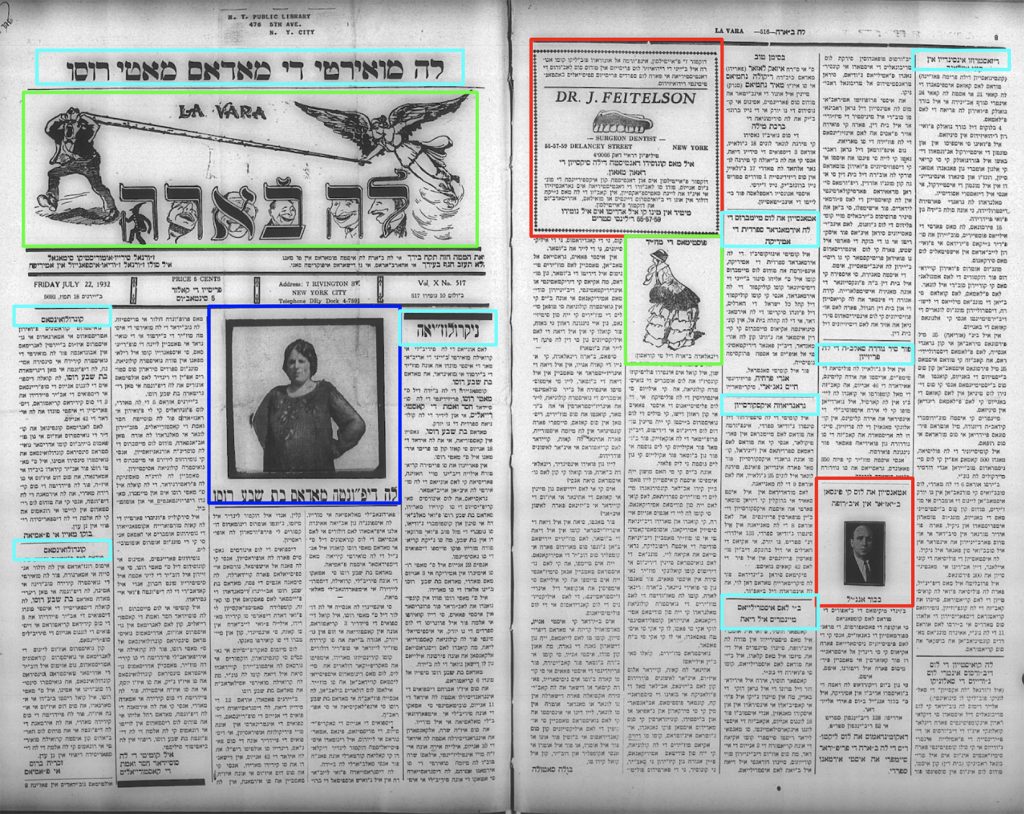
A simulated example of annotations made by the Newspaper Navigator machine learning model on a sample page from La Vara published in 1932.
In total, I processed 15,820 Ladino newspaper pages utilizing this trained machine learning model. A full breakdown of processed pages can be found below in Table 1, and a breakdown of the identified visual content can be found below in Table 2. Professor Naar and I hope to make all of the extracted visual content available as a public dataset for both researchers and the public in the future.
Table 1: Newspaper Titles & Pages Processed
| Newspaper Title | # of Pages |
| El Instruktor revista siyentifika i literaria | 331 |
| El jugeton, Jurnal umoristiko | 4 |
| El Kirbatch Americano (1915 – 1917) | 206 |
| El Luzero Sefaradi (1926 – 1927) | 56 |
| El Progresso / Yosef Daat | 332 |
| El Tiempo (1890 – 1901) | 3,629 |
| La boz de Oriente (1931 – 1932) | 860 |
| La Vara (1922 – 1949) | 10,402 |
| Total | 15,820 |
Table 2: Extracted Visual Content by Type
| Visual Content Type | # Identified |
| Photographs | 348 |
| Illustrations | 52 |
| Maps | 27 |
| Comics | 10 |
| Editorial Cartoons | 8 |
| Advertisements | 18,381 |
| Total | 18,826 |
Analyzing the extracted visual content
With this extracted visual content, the next question is how we can search over it to learn about Sephardic print history. Fortunately, we can utilize machine learning methods to analyze images and cluster them by similarity to one another.
Figure 2a below shows a visualization of 348 photographs identified by the Newspaper Navigator machine learning model. If we zoom in, as shown in the following figures, we find clusters of portrait shots of people, wartime photographs, and crowds or groups of people. Professor Naar and I are currently using these methods to understand print history at a scale previously not possible, uncovering trends within and between newspapers.

Figure 2a. A visualization of the 348 photographs identified by the visual content recognition model with confidence scores greater than 90% (i.e., where misidentifications are unlikely), grouped by the visual similarity of content.

Figure 2b. A magnified cluster within Figure 2a consisting of photographs of groups of people.

Figure 2c. A magnified cluster from within Figure 2a consisting of wartime photographs.

Figure 2d. A magnified cluster from within Figure 2a consisting of portrait shots of people.
Highlighting the Sephardic experience through machine learning
Sephardic Studies has long faced challenges surrounding digitized Ladino texts. In particular, algorithms known as optical character recognition (OCR) engines, used across the world to automate the transcription of typewritten documents, consistently fail on Ladino texts because the underlying Rashi script is interpreted as Hebrew.
Whereas scholars working with digitized materials in many other languages can search by keyword with relative ease, scholars of the Sephardic Jewish experience have been restricted to close readings and searching page by page. This unevenness reflects what is known as algorithmic bias: machine learning models that perpetuate bias due to human decisions behind how they are trained (for example, the composition of training data). Thus, the field of Sephardic Studies — already marginal within Jewish Studies — is further marginalized by existing algorithms.
Professor Naar and I are using machine learning to study the visual content in Ladino newspapers in order to actively push back against this algorithmic marginalization. It is our hope that our collaboration offers an alternative that instead recovers and highlights Sephardic voices. By studying this visual content, we will continue to uncover Sephardic communities, from the people and events found within photographs to local businesses found within advertisements.
 Ben Lee is a third-year Ph.D. student in the Paul G. Allen School for Computer Science & Engineering at the University of Washington, as well as a 2020 Innovator-in-Residence at the Library of Congress. His research lies at the intersection of machine learning and human-computer interaction, with application to cultural heritage and the digital humanities. Ben graduated from Harvard College in 2017 and has served as the inaugural Digital Humanities Associate Fellow at the United States Holocaust Memorial Museum, as well as a Visiting Fellow in Harvard’s History Department. He is currently a National Science Foundation Graduate Research Fellow, and is the Stroum Center’s 2020-2021 Richard and Ina Willner Memorial Fellow in Jewish Studies.
Ben Lee is a third-year Ph.D. student in the Paul G. Allen School for Computer Science & Engineering at the University of Washington, as well as a 2020 Innovator-in-Residence at the Library of Congress. His research lies at the intersection of machine learning and human-computer interaction, with application to cultural heritage and the digital humanities. Ben graduated from Harvard College in 2017 and has served as the inaugural Digital Humanities Associate Fellow at the United States Holocaust Memorial Museum, as well as a Visiting Fellow in Harvard’s History Department. He is currently a National Science Foundation Graduate Research Fellow, and is the Stroum Center’s 2020-2021 Richard and Ina Willner Memorial Fellow in Jewish Studies.






Very much enjoyed learning about your project. While the discussion of algorithms is way beyond my realm, your placing that discussion in the context of the bias in algorithms to further marginalize minority groups, in this case Sephardic culture, is elucidating and clearly a meaningful project in this moment in time.